The object Data Type#
In our previous readings, we introduced the idea that not only can DataFrames and Series hold any of the numeric data types we’ve come to know and love from numpy — like float64 or int64 — but that they can also hold arbitrary Python objects in an object-type Series.
The object type Series gives pandas incredible flexibility as it allows any type of data to be stored in a table. The most common use of the object data type is to store text — for example, names, addresses, written answers, etc. — but the flexibility can also be used for applications like geospatial analysis, in which a single row of a DataFrame may represent a single country, the columns may represent features of the country (name, income, population), and the last column stores geometric Python objects that describe the shape and location of the country.
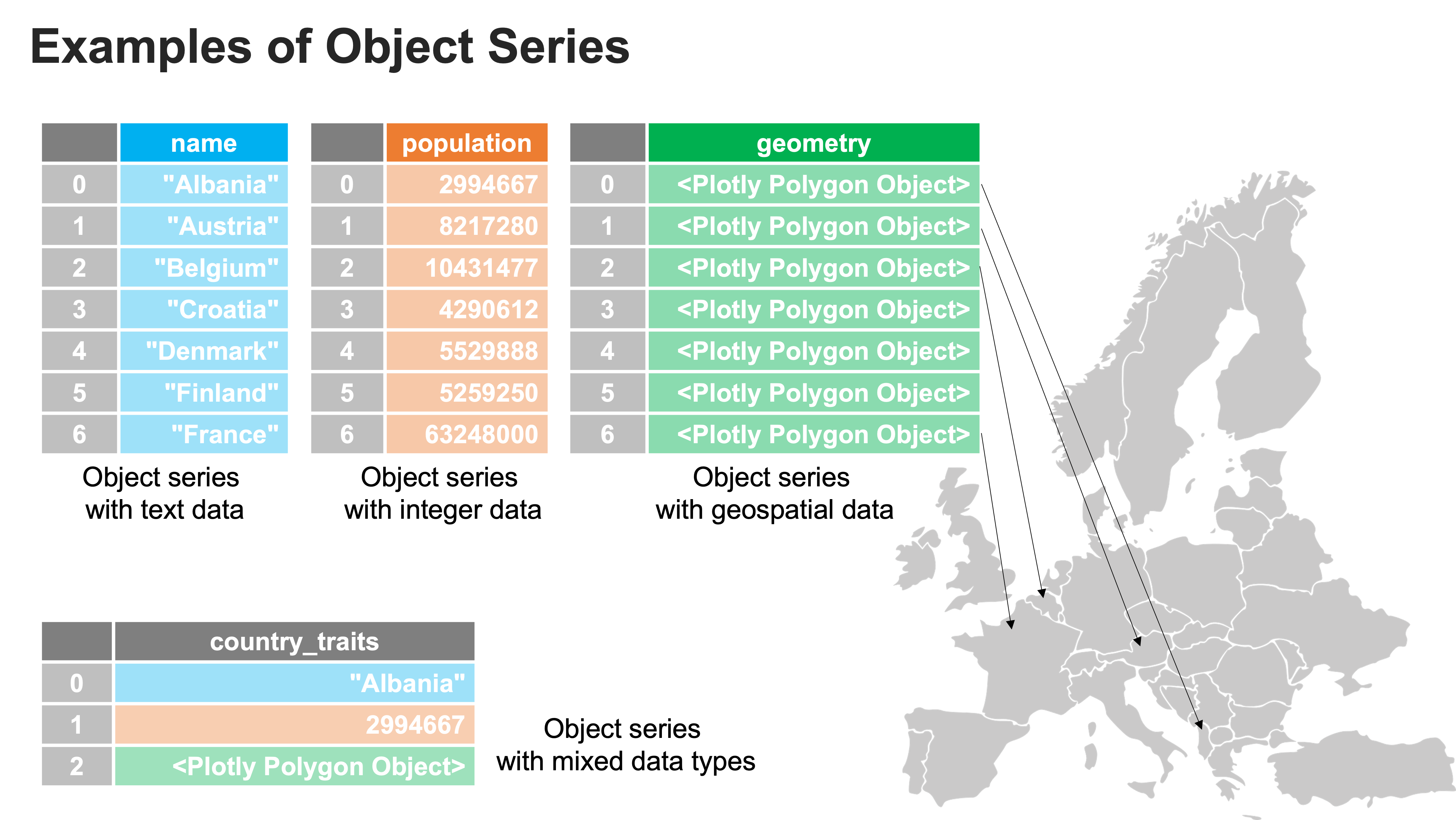
But this flexibility also comes at a cost — performance and memory efficiency.
The object Performance Penalty#
To understand why object Series are slow, it helps to first discuss why numeric Series (and numeric numpy arrays) are fast.
When you work with a numeric pandas Series or numpy array, all of the entries in those arrays live in the same place in memory (in your computer’s RAM). This is possible because all those integers (or all those floating point numbers) are written with the same number of 0s and 1s. In an int64 Series, for example, every integer is represented by 64 1s and 0s. This makes it easy for the computer to lay them out sequentially. Moreover, it makes it possible for the computer to find specific entries quickly, since it knows that the third integer in the Series will start 64 * 2 spots from the start of the Series and end 64 spots later.
But an object Series is a little different. Python objects vary in size — some may only take up 128 0s and 1s, while others may require thousands — and so the actual data in an object Series can’t be laid down in a nice regularly spaced sequence. Instead, every entry in an object Series gets put in a different location in your computer’s memory (RAM), and only the address of that information is placed in a nice organized Series. These addresses are all the same size, and so the addresses can be organized in a regular manner, even if the actual content you want to store is irregular.
The cost of this arrangement is that if you ask for the second entry of an object Series (e.g., my_series.iloc[1]), you’re computer has first go to the second location in the array, read the address stored there, then go to that address to find the actual content you want. And those added steps waste time.
The other problem with object Series is that because they can store anything, Python doesn’t know before it looks up an entry whether it will find a string, an integer, or a Python set. As a result, when it sees code like:
my_array * 2
Python can’t be sure what is meant by * — it could mean “do integer multiplication” (if a given entry in my_array is an integer), but it might also mean “double up the list you find” (if the entry is a Python list)!
Indeed we can see this if we make a numpy object array full of ints and compare it to a numpy integer array. The both have the same content, but they are organized in memory differently:
import pandas as pd
import numpy as np
object_numbers = pd.Series(np.arange(1000000), dtype="object")
numbers = pd.Series(np.arange(1000000), dtype="int64")
%timeit object_numbers * 2
15.9 ms ± 70.2 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit numbers * 2
771 µs ± 9.62 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
See? Same operation (doubling each entry of arrays with the integers from 0 to 1,000,000), but the object array operation is ~20x slower.
So yes, object dtypes are absolutely wonderful and introduce unbelievable flexibility to pandas; but remember there is a cost to using them, so stick to numeric data types when possible!