Merging Data to Understand the Relationship between Drug Legalization and Violent Crime¶
In recent years, many US states have decided to legalize the use of marijuana.
When these ideas were first proposed, there were many theories about the relationship between crime and the “War on Drugs” (the term given to US efforts to arrest drug users and dealers over the past several decades).
In this exercise, we’re going to test a few of those theories using drug arrest data from the state of California.
Though California has passed a number of laws lessening penalities for marijuana possession over the years, arguably the biggest changes were in 2010, when the state changed the penalty for possessing a small amount of marijuana from a criminal crime to a “civil” penality (meaning those found guilty only had to pay a fine, not go to jail), though possessing, selling, or producing larger quantities remained illegal. Then in 2016, the state fully legalized marijuana for recreational use, not only making possession of small amounts legal, but also creating a regulatory system for producing marijuana for sale.
Proponents of drug legalization have long argued that the war on drugs contributes to violent crime by creating an opportunity for drug dealers and organized crime to sell and distribute drugs, a business which tends to generate violence when gangs battle over territory. According to this theory, with drug legalization, we should see violent crime decrease after legalization in places where drug arrests had previously been common.
To be clear, this is far from the only argument for drug legalization! It is simply the argument we are well positioned to analyze today.
Gradescope Autograding¶
Please follow all standard guidance for submitting this assignment to the Gradescope autograder, including storing your solutions in a dictionary called results and ensuring your notebook runs from the start to completion without any errors.
For this assignment, please name your file exercise_merging.ipynb before uploading.
You can check that you have answers for all questions in your results dictionary with this code:
assert set(results.keys()) == {
"ex6_validate_keyword",
"ex10_merged_successfully",
"ex16_num_obs",
"ex17_drug_change",
"ex18_violent_change",
"ex21_diffindiff",
"ex23_diffindiff_proportionate",
}
Submission Limits¶
Please remember that you are only allowed three submissions to the autograder. Your last submission (if you submit 3 or fewer times), or your third submission (if you submit more than 3 times) will determine your grade Submissions that error out will not count against this total.
Pre-Legalization Analysis¶
Exercise 1¶
We will begin by examining county-level data on arrests from California in 2009. This data is derived directly from data hosted by the Office of the California State Attorney General, but please follow the github link above and download and import the file ca_arrests_2009.csv (don’t try and get it directly from the State Attorney General’s office).
Exercise 2¶
Use your data exploration skills to get a feel for this data. If you need to, you can find the original codebook here (This data is a version of that data, but collapsed to one observation per county.)
Exercise 3¶
Figuring out what county has the most violent arrests isn’t very meaningful if we don’t normalize for size. A county with 10 people and 10 arrests for violent crimes is obviously worse than a county with 1,000,000 people an 11 arrests for violent crime.
To address this, also import nhgis_county_populations.csv from the directory we’re working from.
Exercise 4¶
Use your data exploration skills to get used to this data, and figure out how it relates to your 2009 arrest data.
Exercise 5¶
Once you feel like you have a good sense of the relation between our arrest and population data, merge the two datasets.
Exercise 6¶
When merging data, the result will only be meaningful if your understanding of how the data sets you are merging relate to one another are correct. In some ways, this is obvious — for example, if the variable(s) that you are using to merge observations in the two datasets or to actually identifying observations that should be linked, then obviously merging using those variables will create a meaningless new dataset.
But other properties that matter are often more subtle. For example, it’s important to figure out whether your merge is a 1-to-1 merge (meaning there is only one observation of the variable you’re merging on in both datasets), a 1-to-many merge (meaning there is only one observation of the variable you’re merging on in the first dataset, but multiple observations in the second), or a many-to-many merge (something you almost never do).
Being correct in your assumptions about these things is very important. If you think there’s only one observation per value of your merging variable in each dataset, but there are in fact 2, you’ll end up with two observations for each value after the merge. Moreover, not only is the structure of your data now a mess, but the fact you were wrong means you didn’t understand something about your data.
So before running a merge, it is critical to answer the following questions:
What variable(s) do you think will be consistent across these two datasets you can use for merging?
Do you think there will be exactly 1 observation for each value of this variable(s) in your arrest data?
Do you think there will be exactly 1 observation for each value of this variable(s) in your population data?
So in markdown, answer these three questions for this data.
Then also specify the type of merge you were hoping to accomplish as one of the following strings — "one-to-one", "one-to-many", "many-to-one", or "many-to-many" — in your results dictionary under the key "ex6_validate_keyword". Assume that the first dataset we are talking about (e.g., the one in one-to-many, if that were your selection) is your arrests data and the second dataset (e.g., the many in one-to-many, if that were your selection).
Merge Validation¶
Because of the importance of answering these questions accurately, pandas provides a utility for validating these assumptions when you do a merge: the validate keyword! Validate will accept "1:1", "1:m", "m:1", and "m:m". It will then check to make sure your merge matches the type of merge you think it is. I highly recommend always using this option (…and not just because I’m the one who added validate to pandas).
Note: validate only actually tests if observations are unique when a 1 is specified; if you do a 1:1 merge but pass validate="1:m", validate="m:1", or validate="m:m", you won’t get an error — a one-to-many merge that turns out to be a one-to-one isn’t nearly as dangerous as a one-to-one merge that turns out to be one-to-many.
Exercise 7¶
Repeat the merge you conducted above, but this time use the validate to make sure your assumptions about the data were correct. If you find that you made a mistake, revise your data until the merge you think is correct actually takes place.
To aid the autograder, please make sure to comment out any code that generates an error.
Exercise 8¶
Were your assumptions about the data correct? If not, what had you (implicitly) assumed when you did your merge in Exercise 5 that turned out not to be correct?
Merge Diagnostics¶
Exercise 9¶
Checking whether you are doing a 1-to-1, many-to-1, 1-to-many, or many-to-many merge is only the first type of diagnostic test you should run on every merge you conduct. The second test is to see if you data merged successfully!
To help with this, the merge function in pandas offers a keyword option called indicator. If you set indicator to True, then pandas will add a column to the result of your merge called _merge. This variable will tell you, for each observation in your merged data, whether:
that observation came from a successful merge of both datasets,
if that observation was in the left dataset (the first one you passed) but not the right dataset (the second one you passed), or
if that observation was in the right dataset but not the left.
This allows you to quickly identify failed merges!
For example, suppose you had the following data:
[1]:
import pandas as pd
import numpy as np
pd.set_option("mode.copy_on_write", True)
df1 = pd.DataFrame({"key": ["key1", "key2"], "df1_var": [1, 2]})
df1
[1]:
| key | df1_var | |
|---|---|---|
| 0 | key1 | 1 |
| 1 | key2 | 2 |
[2]:
df2 = pd.DataFrame({"key": ["key1", "Key2"], "df2_var": ["a", "b"]})
df2
[2]:
| key | df2_var | |
|---|---|---|
| 0 | key1 | a |
| 1 | Key2 | b |
Now suppose you expected that all observations should merge when you merge these datasets (because you hadn’t noticed the typo in df2 where key2 has a capital Key2. If you just run a merge, it works without any problems:
[3]:
new_data = pd.merge(df1, df2, on="key", how="outer")
And so you might carry on in life unaware your data is now corrupted: instead of two merged rows, you now have 3, only 1 of which merged correctly!
[4]:
new_data
[4]:
| key | df1_var | df2_var | |
|---|---|---|---|
| 0 | key1 | 1.0 | a |
| 1 | key2 | 2.0 | NaN |
| 2 | Key2 | NaN | b |
When what you really wanted was:
[5]:
df2_correct = df2.copy()
df2_correct.loc[df2.key == "Key2", "key"] = "key2"
pd.merge(df1, df2_correct, on="key", how="outer")
[5]:
| key | df1_var | df2_var | |
|---|---|---|---|
| 0 | key1 | 1 | a |
| 1 | key2 | 2 | b |
(in a small dataset, you’d quickly see you have 1 row instead of 2, but if you have millions of rows, a couple missing won’t be evident).
But now suppose we use the indicator function:
[6]:
new_data = pd.merge(df1, df2, on="key", how="outer", indicator=True)
new_data._merge.value_counts()
[6]:
_merge
left_only 1
right_only 1
both 1
Name: count, dtype: int64
We could immediately see that only one observation merged correct, and that one row from each dataset failed to merge!
Moreover, we can look at the failed merges:
[7]:
new_data[new_data._merge != "both"]
[7]:
| key | df1_var | df2_var | _merge | |
|---|---|---|---|---|
| 1 | key2 | 2.0 | NaN | left_only |
| 2 | Key2 | NaN | b | right_only |
Allowing us to easily diagnose the problem.
Note: The pandas merge function allows users to decide whether to keep only observations that merge (how='inner'), all the observations from the first dataset pasted to merge (how='left'), all the observations from the second dataset passed to merge (how='right'), or all observations (how='outer'):
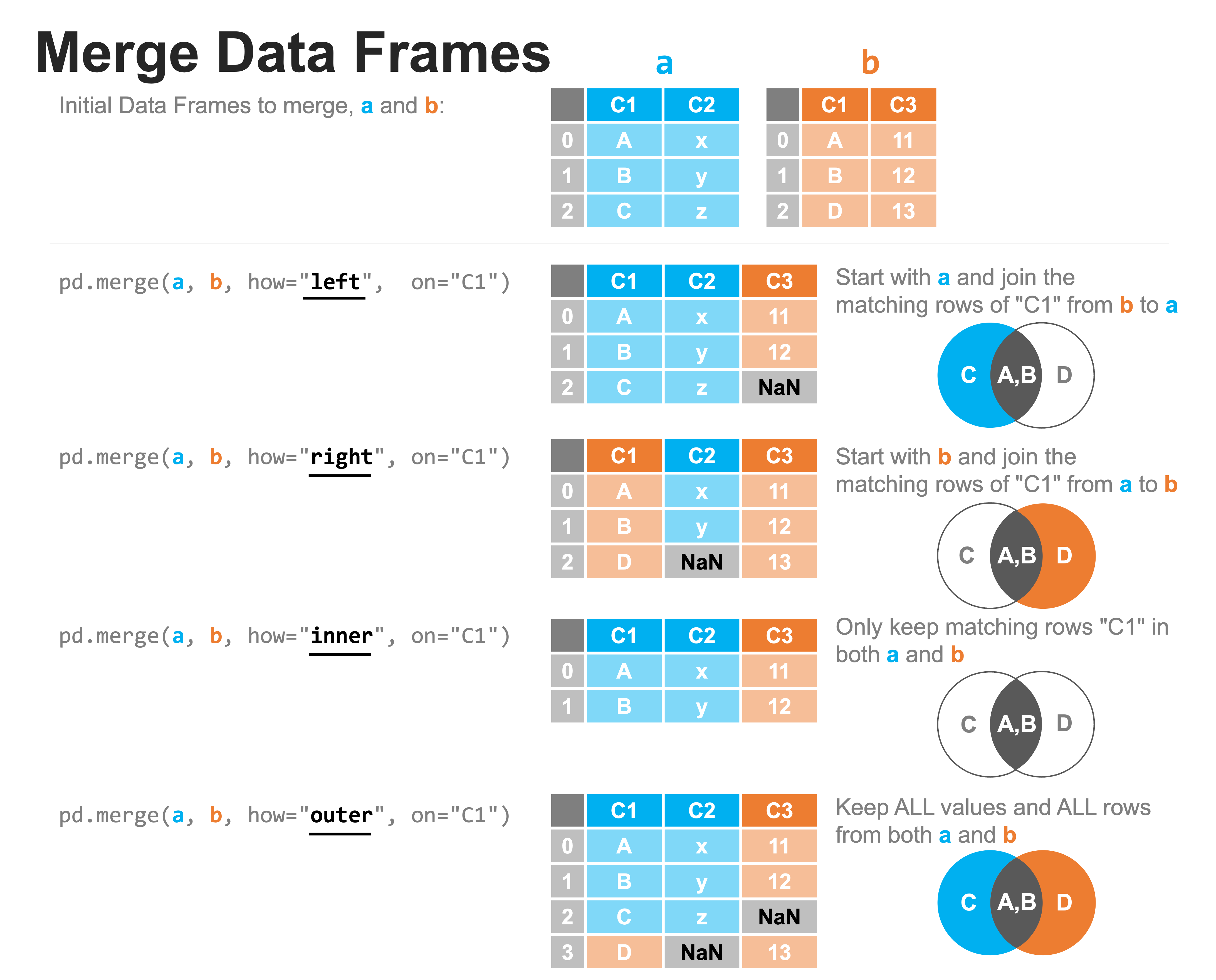
But one danger to using the more restrictive options (like the default, how='inner') is that the merge throws away all the observations that fail to merge, and while this may be the eventual goal of your analysis, it means that you don’t get to see all the observations that failed to merge that maybe you thought would merge. In other words, it throws away the errors so you can’t look at them!
So to use indicator effectively, you have to:
Not use
how="inner", andCheck the values of
_mergeafter your merge.
Exercise 10¶
Now repeat your previous merge using both the validate keyword and the indicator keyword with how='outer'.
How many observations successfully merged (were in both datasets)? Store the result in results under the key "ex10_merged_successfully".
Exercise 11¶
You should be able to get to the point that all counties in our arrest data merge with population data. If that did not happen, can you figure out why that did not happen? Can you fix the data so that all arrest data merges with population data?
Comparing Arrest Rates¶
Exercise 12¶
Now that we have arrest counts and population data, we can calculate arrest rates. For each county, create a new variable called violent_arrest_rate_2009 that is the number of violent arrests for 2009 divided by the population of the county from 2005-2009, and a similar new variable called drug_arrest_rate_2009 for drug arrests divided by population.
Exercise 13¶
Make a scatter plot that shows the relationship between each county’s violent arrest rate and it’s drug arrest rate. Since we haven’t done a lot with plotting yet, feel free to plot in whatever manner feels most comfortable. The easiest, if you’re unsure, is just to use the pandas inbuilt .plot() method. Just specify the x keyword with your x-axis variable, the y keyword with your y-axis variable, and use kind="scatter".
Exercise 14¶
Based on this simple comparison of 2009 violent arrest rates and drug arrest rates, what might you conclude about the relationship between the illegal drug trade and violent crime?
Comparing with 2018 Arrests¶
The preceding analysis can tell us about whether violent crime and the drug trade are correlated, but it doesn’t tell us much about whether they are causally related. It could be the case that people dealing drugs cause more violent crime, but it could also be that certain communities, for some other reason, tend to have both more drug sales and more violent crime.
To help answer this question, let’s examine whether violent crime arrest rates changed in response to drug legalization. In particular, let’s do this by comparing violent crime arrest rates in 2009 (before drug legalization) to violent crime arrest rates in 2018 (after drug legalization). If the illegal drug trade causes violent crime, then we would expect the violent crime rate to fall in response to drug legalization.
Exercise 15¶
Just as we created violent arrest rates and drug arrest rates for 2009, now we want to do it for 2018. Using the data on 2018 arrests (also in the same repository we used before) and the same dataset of population data (you’ll have to use population from 2013-2017, as 2018 population data has yet to be released), create a dataset of arrest rates.
As before, be careful with your merges!!!
Exercise 16¶
Now merge our two county-level datasets so you have one row for every county, and variables for violent arrest rates in 2018, violent arrest rates in 2009, felony drug arrest rates in 2018, and felony drug arrest rates in 2009. Store the number of observations in your final data set in your results dictionary under the key "ex16_num_obs".
Exercise 17¶
Did drug arrests go down from 2009 to 2018 in response to drug legalization? (they sure better! This is what’s called a “sanity check” of your data and analysis. If you find drug arrests went up, you know something went wrong with your code or your understanding of the situations).
Store the average county-level change in drug arrests per capita in results under the key "ex17_drug_change".
Exercise 18¶
Now we want to look at whether violent crime decreased following drug legalization. Did the average violent arrest rate decrease? By how much? (Note: We’re assuming that arrest rates are proportionate to crime rates. If policing increased so that there were more arrests per crime committed, that would impact our interpretation of these results. But this is just an exercise, so…)
Store the average county-level change in violent arrests per capita in results under the key "ex18_violent_change"
Exercise 19¶
Based on your answers to exercises 17 and 18, what might you conclude about the relationship between the illegal drug trade and violent crime? Did legalizing drugs increase violent crime (assuming arrest rates are a good proxy for crime rates)? Decrease violent crime? Have no effect?
Difference in Difference Analysis¶
The preceding analysis is something we sometimes call a “pre-post” analysis, in that it is a comparison of how and outcome we care about (violent arrest rates) changes from before a treatment is introduced (“pre”) to after (“post”). BUT: pre-post comparisons are imperfect. If we knew that violent crime was not going to change at all in a world without drug legalization, then this comparison is perfectly valid. But what if, absent drug legalization, violent crime would have fallen on its own (maybe because of advances in policing practices or a better economy)? Or maybe it would have increased?
This is actually a very common problem. For example, imagine you’re trying to figure out whether taking tylenol helps with headaches. You have a patient with a headache, you give them tylenol, and then the next day you ask them if they still have a headache, and find out that they don’t — does that mean that tylenol cured the headache? Maybe… but most headaches eventually resolve on their own, so maybe the headache would have passed with or without the patient taking tylenol! In fact, there’s a term for this phenomenon in medicine — the “natural history” of a disease, which is the trajectory that we think a disease might follow absent treatment. And the natural history of the disease is almost never for it to stay exactly the same indefinitely.
(All of this is closely related to the discipline of causal inference, and if it makes your head to hurt, don’t worry — that means you’re doing it right! We will talk lots and lots more about it in the weeks and months to come.)
One way to try to overcome this problem is with something called a difference-in-difference analysis. Rather than just looking at whether violent drug arrest rates increase or decrease between 2009 and 2018, we can split our sample of counties into those that were more impacted by drug legalization and those that were less impacted by drug legalization and evaluate whether we see a greater change in the violent drug arrest rate in the counties that were more impacted.
What does it mean to have been “more impacted” by drug legalization? In this case, we can treat the counties that had higher drug arrest rates in 2009 as counties that were more impacted by drug legalization than those that had low drug arrest rates in 2009. After all, in a county that had no drug arrests, legalization wouldn’t do anything, would it?
Exercise 20¶
First, split our sample into two groups: high drug arrests in 2009, and low drug arrests in 2009 (cut the sample at the average drug arrest rate in 2009).
Exercise 21¶
Now, determine weather violent crime changed more from 2009 to 2018 in the counties that had lots of drug arrests in 2009 (where legalization likely had more of an effect) than in counties with fewer drug arrests in 2009 (where legalization likely mattered less)?
Calculate this difference-in-difference:
(the change in violent crime rate per capita for counties with lots of drug arrests in 2009)
- (the change in violent crime rate per capita for counties with few drug arrests in 2009)
Store your “difference-in-difference” estimate in your results dictionary under the key "ex21_diffindiff".
Exercise 22¶
Interpret your difference in difference result.
Exercise 23¶
The quantity we estimated above is a little difficult to interpret. Rather than calculating the absolute change in violent arrest rates per capita, let’s calculate the proportionate change.
Calculate:
(the county-level percentage change in violent crime rate with lots of drug arrests in 2009)
- (the county-level percentage change in violent crime rate with few drug arrests in 2009)
Store your “difference-in-difference” estimate in your results dictionary under the key "ex24_diffindiff_proportionate". Report your result in percentages, such that a value of -100 would imply that the average county experienced a 100% decrease in the violent arrest rate.